Dans cet article, nous allons détailler le script ligne par ligne. Le script complet se trouve en bas de page.
Tout d’abord, on indique dans le programme environnement dans lequel nous allons travailler. Comme notre langage est le bash, on indique dans la première ligne :
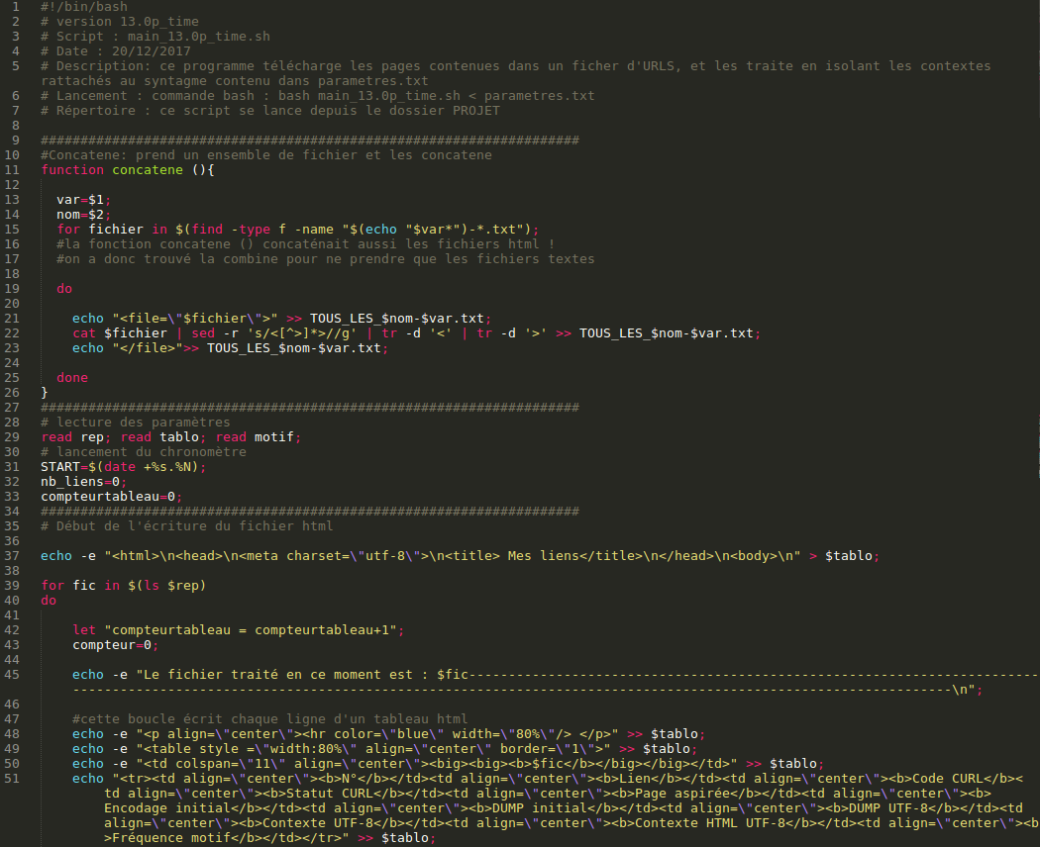
#!/bin/bash
Ensuite, on écrit les fonctions. Nous n’en avons qu’une ici : concatene ( ) (2)
Cette fonction prend 2 variables : le chiffre correspondant aux contextes d’une langue : (1 pour l’anglais, 2 pour le français 3 pour le chinois) et le nom du fichier que l’on veut en sortie.
Cette fonction va prendre tous les fichiers correspondant à une langue et aux contextes et va les concaténer (concatène 1-1.txt, 1-2.txt, 1-3.txt, …).
Pour commencer, on lance l’instruction dans une boucle for :
Pour tous les fichiers qui sont du type *chiffre de la variable*.txt :
on écrit dans le fichier final (par ex TOUS_LES_CONTEXTES-1) la balise « »
on imprime dans le fichier final le contenu du fichier en enlevant d’éventuelles balises grâce à la commande « sed »
on écrit dans le fichier final la balise fermante .
On répète ces instructions pour tous les fichiers que la commande va trouver.
function concatene (){
var=$1;
nom=$2;
for fichier in $(find -type f -name "$(echo "$var*")-*.txt");
#la fonction concatene () concaténait aussi les fichiers html !
#on a donc trouvé la combine pour ne prendre que les fichiers textes
do
echo "" >> TOUS_LES_$nom-$var.txt;
cat $fichier | sed -r 's/]*>//g' | tr -d '' >> TOUS_LES_$nom-$var.txt;
echo "">> TOUS_LES_$nom-$var.txt;
done
}
Après avoir initialisé cette fonction, on va lire les paramètres qui seront envoyés lorsque l’on lancera le programme depuis le terminal (via bash programme.sh < parametres.txt)
read rep; read tablo; read motif;
- rep : le répertoire qui est utilisé
- tablo : le nom du fichier HTML qui contiendra les liens
- motif : l’expression régulière correspondant à notre syntagme
Notre fichier paramètres : 
Ensuite on commence le programme.
Tout d’abord, on retient l’heure exacte du lancement du programme (afin de savoir en combien de temps il s’exécute) en sauvegardant sa valeur dans la variable START.
START=$(date +%s.%N);
On initialise ensuite deux variables :
nb_liens=0; compteurtableau=0;
- nb_liens : le nombre de liens, qui sera incrémenté à chaque nouveau lien que l’on traitera
- compteur_tableau : qui servira à indiquer de quelle langue on s’occupera (cette variable ira de 1 à 3).
Ensuite, on écrase tout ce qui était contenu dans le tableau précédant en remplaçant d’éventuelles lignes du tableau (le fichier HTML) par les informations de début de page html.
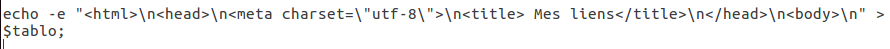
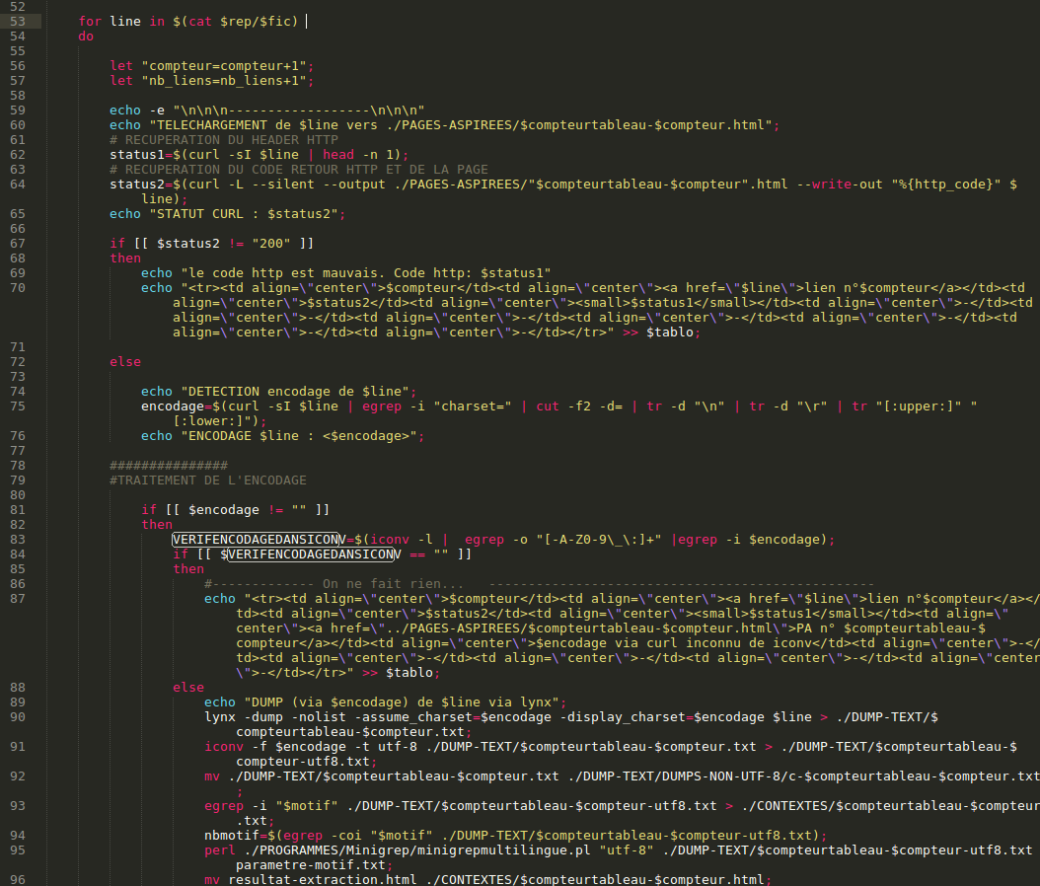
Ensuite, on lance une boucle for :
Pour tous les fichiers dans le répertoire (le dossier d’URLS qui contient 3 fichiers textes d’URLS):
On incrémente la variable compteur_tableau.
On initialise la variable compteur qui correspondra à chaque URLS :
for fic in $(ls $rep) do let "compteurtableau = compteurtableau+1"; compteur=0;
Ensuite on affiche à l’écran le fichier qui est traité en ce moment grâce à la commande :
echo -e "Le fichier traité en ce moment est : $fic---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------\n";
Ensuite on va écrire le début du code HTML qui correspond à chaque tableau :

Ce qui correspond à l’Output suivant sur le fichier HTML : 
(Nous ne pouvons malheureusement pas écrire toutes le commande en format préformaté : WordPress analyse celle qui contiennent un code HTML et les exécute, ce que nous ne voulons pas).
Après ce, on lance une deuxième boucle for qui traitera chaque ligne du fichier d’URLS (une ligne = une URLS) :
for line in $(cat $rep/$fic) do
On incrémente alors les variables nb_liens et compteur :
let "compteur=compteur+1"; let "nb_liens=nb_liens+1";
Ensuite on récupère le header correspondant à l’URL avec :
status1=$(curl -sI $line | head -n 1);
On télécharge ensuite la page web et on la sauvegarde dans le répertoire /PAGES-ASPIREES. Au passage, on récupère le code retour http (qui est égal à 200 si tout se passe bien).
status2=$(curl -L --silent --output ./PAGES-ASPIREES/"$compteurtableau-$compteur".html --write-out "%{http_code}" $line); echo "STATUT CURL : $status2";
On lance après la condition suivante : si le code retour http n’est pas égal à 200, alors on ne traitera pas cette URL (nous avons fais ce choix pour être sur de n’avoir que des données parfaites), et on écrit une ligne vide dans le tableau HTML :

Si le code est égal à 200, alors on commence le traitement :On décode tout d’abord l’encodage de la page via curl :
echo "DETECTION encodage de $line"; encodage=$(curl -sI $line | egrep -i "charset=" | cut -f2 -d= | tr -d "\n" | tr -d "\r" | tr "[:upper:]" "[:lower:]"); echo "ENCODAGE $line : ";
On lance alors la condition suivante : si l’encodage est différent de la chaîne de caractères vide alors on va piocher dans la liste de tous les encodages traités par iconv celui qui correspond à la variable encodage. On associe cette valeur à la variable VERIFENCODAGEDANSICONV
if [[ $encodage != "" ]] then VERIFENCODAGEDANSICONV=$(iconv -l | egrep -o "[-A-Z0-9\_\:]+" |egrep -i $encodage);
Si cette valeur est la chaîne de caractère nulle, on ne fera rien, et on indiquera une ligne vide dans le tableau :
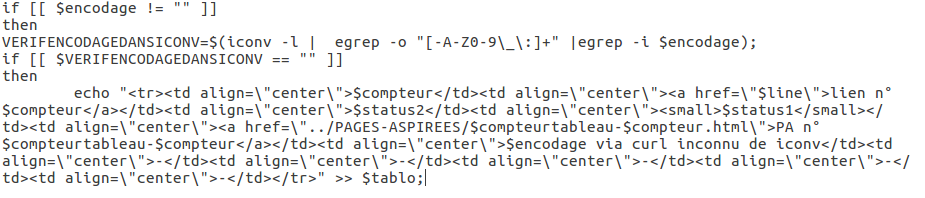
Sinon, on lancera le traitement (2) :On commence par récupérer le DUMP via la commande lynx et on le sauvegarde dans le répertoire DUMP-TEXT :
else echo "DUMP (via $encodage) de $line via lynx"; lynx -dump -nolist -assume_charset=$encodage -display_charset=$encodage $line > ./DUMP-TEXT/$compteurtableau-$compteur.txt;
Ensuite on le convertir de son encodage de base vers UTF-8 :
iconv -f $encodage -t utf-8 ./DUMP-TEXT/$compteurtableau-$compteur.txt > ./DUMP-TEXT/$compteurtableau-$compteur-utf8.txt;
Si cet encodage a été convertit (il aurait peu être en utf-8), alors on va déplacer son fichier original vers le dossier DUMPS-NON-UTF-8 et on va ajouter le caractère « c » en début de son nom de fichier :
mv ./DUMP-TEXT/$compteurtableau-$compteur.txt ./DUMP-TEXT/DUMPS-NON-UTF-8/c-$compteurtableau-$compteur.txt
On récupère le contexte via la variable motif et la commande egrep. On compte aussi le nombre de fois que ce motif est présent :
egrep -i "$motif" ./DUMP-TEXT/$compteurtableau-$compteur-utf8.txt > ./CONTEXTES/$compteurtableau-$compteur.txt; nbmotif=$(egrep -coi "$motif" ./DUMP-TEXT/$compteurtableau-$compteur-utf8.txt;
On utilise maintenant le programme minigrep (afin d’avoir un joli format de contexte) via la commande Perl :
perl ./PROGRAMMES/Minigrep/minigrepmultilingue.pl "utf-8" ./DUMP-TEXT/$compteurtableau-$compteur-utf8.txt parametre-motif.txt;
On déplace le résultat de la commande en le renommant (par défaut le résultat de minigrep est noté resultat-extraction.html) :
mv resultat-extraction.html ./CONTEXTES/$compteurtableau-$compteur.html;
On écrit ensuite les liens dans le tableau :
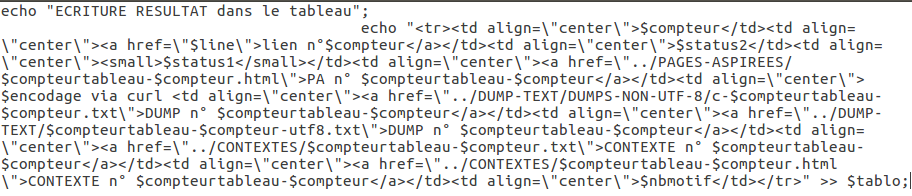
C’était l’étape de traitement de base des données (2), que l’on répétera un peu plus tard.
On ferme ensuite cette boucle if, et on repasse dans la boucle if principale (la variable encodage doit être égale à la chaîne vide).
On cherche à savoir si la page que l’on a aspiré contient un charset (une donnée du code HTML qui contient l’encodage de la page) :
else isthereacharset=$(egrep -i -o "meta(.*)?charset" ./PAGES-ASPIREES/"$compteurtableau-$compteur".html);
Si la valeur de cette variable est différente de la chaîne vide, autrement dit, si il y a un charset indiqué dans la page aspiré, alors on applique la condition suivante :
Si cet encodage est utf-8, alors on réapplique la chaîne de traitement (2) :
if [[ $encodage == "utf-8" ]] then echo "DUMP de $line via lynx"; lynx -dump -nolist -assume_charset=$encodage -display_charset=$encodage $line > ./DUMP-TEXT/$compteurtableau-$compteur.txt; egrep -i "$motif" ./DUMP-TEXT/$compteurtableau-$compteur.txt > ./CONTEXTES/$compteurtableau-$compteur.txt; nbmotif=$(egrep -coi "$motif" ./DUMP-TEXT/$compteurtableau-$compteur.txt); perl ./PROGRAMMES/Minigrep/minigrepmultilingue.pl "utf-8" ./DUMP-TEXT/$compteurtableau-$compteur.txt parametre-motif.txt; mv resultat-extraction.html ./CONTEXTES/$compteurtableau-$compteur.html;

Sinon on va rechercher si cet encodage est dans la liste des encodages acceptés par iconv. S’il n’y est pas, on affiche une ligne vide dans le tableau :
else VERIFENCODAGEDANSICONV=$(iconv -l | egrep -o "[-A-Z0-9\_\:]+" |egrep -i $encodage) ; if [[ $VERIFENCODAGEDANSICONV == "" ]] then

S’il y est, on le convertit avec iconv et on reprend la chaîne de traitement vu en (2) :
lynx -dump -nolist -assume_charset=$encodage -display_charset=$encodage $line > ./DUMP-TEXT/$compteurtableau-$compteur.txt; iconv -f $encodage -t utf-8 ./DUMP-TEXT/$compteurtableau-$compteur.txt > ./DUMP-TEXT/$compteurtableau-$compteur-utf8.txt; mv ./DUMP-TEXT/$compteurtableau-$compteur.txt ./DUMP-TEXT/DUMPS-NON-UTF-8/c-$compteurtableau-$compteur.txt; egrep -i "$motif" ./DUMP-TEXT/$compteurtableau-$compteur-utf8.txt > ./CONTEXTES/$compteurtableau-$compteur.txt; nbmotif=$(egrep -coi "$motif" ./DUMP-TEXT/$compteurtableau-$compteur-utf8.txt); perl ./PROGRAMMES/Minigrep/minigrepmultilingue.pl "utf-8" ./DUMP-TEXT/$compteurtableau-$compteur-utf8.txt parametre-motif.txt; mv resultat-extraction.html ./CONTEXTES/$compteurtableau-$compteur.html ;

On ferme alors les boucles if, et on inscrit dans la page HTML la fermeture du tableau :
fi fi done

done
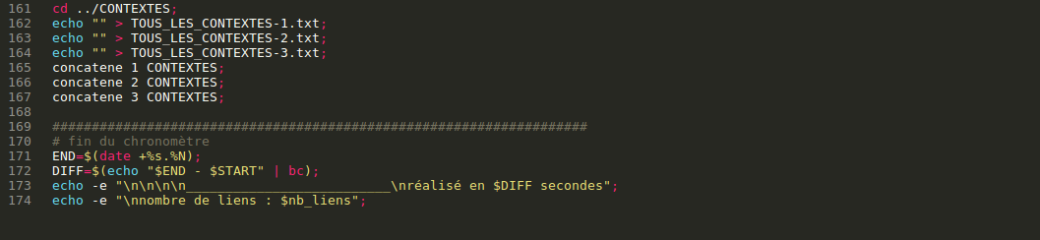
Une fois que l’on a traité toutes les URLS de tous les fichiers d’URLS, on referme la page HTML :

On va alors concaténer tous les DUMPS via la fonction concatene que l’on avait vu en (1) (on écrase tout ce qui aurait pu être dans les fichiers TOUS_LES_DUMPS/CONTEXTES de 1 à 3 grâce à echo « » > *nom du fichier .txt*;)
cd ./DUMP-TEXT; echo "" > TOUS_LES_DUMPS-1.txt; echo "" > TOUS_LES_DUMPS-2.txt; echo "" > TOUS_LES_DUMPS-3.txt; concatene 1 DUMPS; concatene 2 DUMPS; concatene 3 DUMPS; cd ../CONTEXTES; echo "" > TOUS_LES_CONTEXTES-1.txt; echo "" > TOUS_LES_CONTEXTES-2.txt; echo "" > TOUS_LES_CONTEXTES-3.txt; concatene 1 CONTEXTES; concatene 2 CONTEXTES; concatene 3 CONTEXTES;
On arrête alors le chronomètre et on affiche nb_liens nous indique combien de fichiers nous avons traites :
END=$(date +%s.%N); DIFF=$(echo "$END - $START" | bc); echo -e "\n\n\n\n__________________________\nréalisé en $DIFF secondes"; echo -e "\nnombre de liens : $nb_liens";
En général, le temps d’exécution est de 10 minutes.
Exemple d’output sur la console : 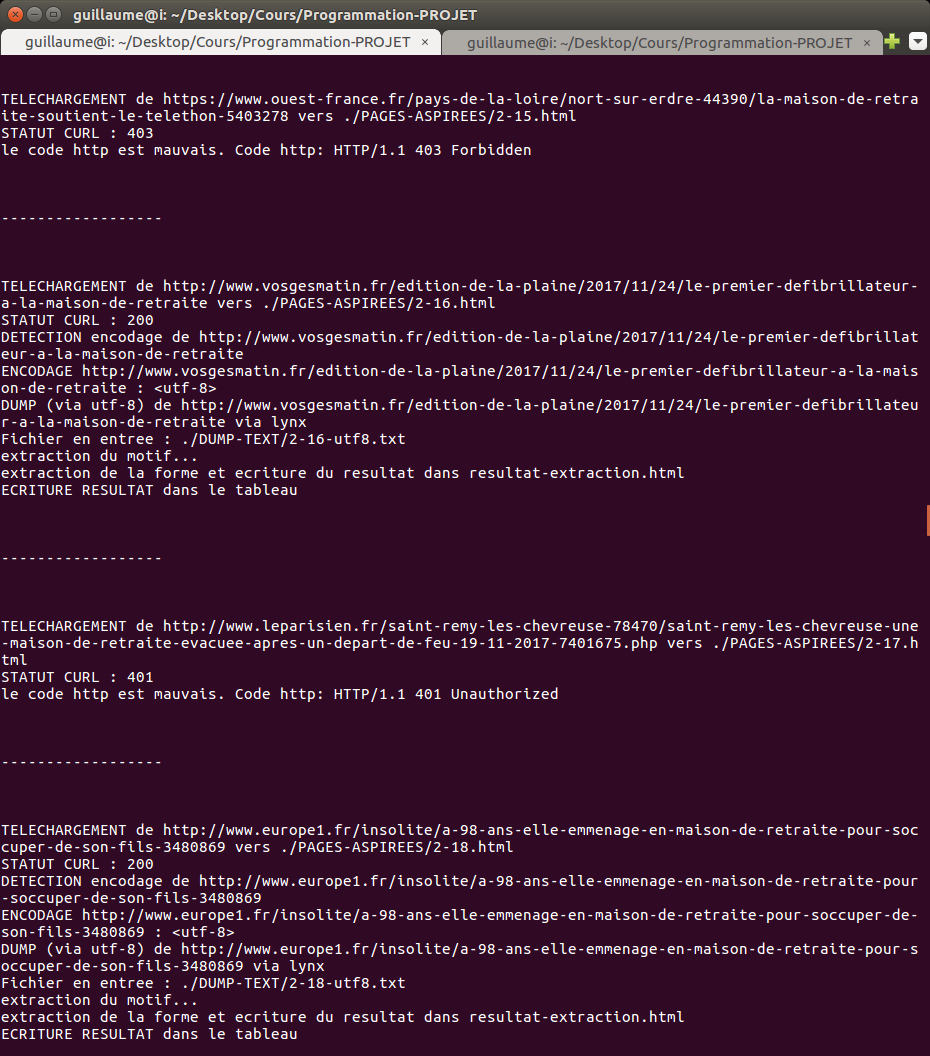 __________________________
__________________________
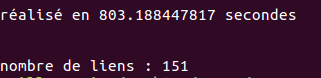 _________________________
_________________________
Script complet