
Dans notre projet nous étions assez frustrés de ne pas travailler directement avec toutes les pages d’un site internet. Nos URLS pointent directement sur l’article en question, alors que nous pensions initialement à traiter un site web entier.
Pour palier à cela, nous allons essayer de télécharger entièrement un site d’actualité et de traiter son contenu de la même manière que nous avons traité nos URLS. On pourra alors comparer les formes associées à notre syntagme dans plusieurs journaux.
Pour ce faire, nous allons commencer par le site lemonde.fr
Il existe une commande linux spécialement dédiée à cette tâche : wget.
On essaye la commande suivante :
wget --mirror https://www.lemonde.fr
–mirror signifie que l’on active toutes les options nécessaires pour la mise en miroir (on peut télécharger de plusieurs serveurs différents).
La commande a téléchargé un fichier texte nommée robots.txt qui contient les lignes suivantes :
# 24/11/2016 # Il est interdit d'utiliser des robots d'indexation Web ou d'autres méthodes automatiques de feuilletage ou de navigation sur ce site Web. # Nous interdisons de crawler notre site Web en utilisant un agent d'utilisateur volé qui ne correspond pas à votre identité.
Il va donc falloir utiliser des astuces pour contourner contre-temps.
On essaye l’option –random-wait qui va attendre un certain temps, différent à chaque essai, avant de télécharger une autre page.
Mais c’est un échec encore une fois.
La solution est donnée par la commande suivante :
wget --mirror -r -e robots=off https://www.lemonde.fr
-r : indique la récursivité, on va chercher dans les autres pages contenues dans l’adresse du site. Par exemple : https://www.lemonde.fr/article-n-3211 ….
-e robots=off : indique qu’il faut ignorer le fichier robots.txt
Après avoir lancé la commande, on se rend compte d’une chose très rapidement : ce site web choisi est très lourd (prend beaucoup de temps à télécharger). Nous avons laissé cette commande s’exécuter pendant 24h, après quoi nous l’avons interrompue.
Le fichier contenant toutes les pages aspirées est assez volumineux : 30 848 items, taille totale 1,9 GB.
Quand on regarde les fichiers qui ont été téléchargés, on peut se douter d’une chose : notre syntagme risque de ne pas être présent dans chaque page aspirée. Néanmoins, nous choisissons de garder ces fichiers. Ils pourraient s’avérer utiles par la suite.
exemple des dossiers récupérés :

Après réflexion, nous aurions pu incorporer cette commande dans un programme qui téléchargerait la page uniquement s’il contient le syntagme recherché, mais maintenant que nous avons récupéré toutes ces pages, nous choisissons de les garder pour les explorer.
De la même manière nous allons lancer une commande similaire sur le site américain washingtonpost.com qui peut être considéré comme un équivalent du journal du monde aux États-Unis.
Commande :
wget --mirror -r https://www.washingtonpost.com
(pas besoin de refuser l’accès aux robots dans ce cas ci)
Nous avions pensé au New York Time, mais ce journal dispose d’une très grande quantité d’archives qui sont sans doute sans importance pour notre étude.
De même que lemonde.fr, ce site contient une très grand quantité d’information. Nous choisissons de stopper son téléchargement après que la taille du dossier soit de 1.9 GB, afin d’avoir une masse de données égale au monde.fr.
Création d’un programme
Cette partie nous a donné beaucoup de fil à retordre* : en effet, comme les articles du monde sont contenus dans les dossiers, qui sont contenus dans des dossiers à l’intérieur de dossiers… nous avons du ruser pour trouver une méthode qui permettrait de naviguer dans les dossiers.
Navigation dans les dossiers :
Nous avons donc créé une fonction récursive qui va traiter les fichier : En gros, ce que fait cette fonction:
– si l’élément est un dossier, alors on l’ouvre et on se positionne dedans, et elle s’appelle elle même pour traiter les éléments de ce dossier :
– si l’élément est un fichier html, on le traite, grâce à la fonction traitement () que l’on verra un peu plus bas
function exploreEtTraite (){
dos=$1;
echo -e "\n"
echo $(pwd);
echo "dos = $dos";
echo -e "fichiers contenus :\n\n$(ls)";
for fic in $(ls)
do
echo "________________________________";
echo "$fic";
echo $(pwd);
if [ -d ./$fic ] #est-ce un dossier ? :
then
echo "$fic est un dossier, on l'ouvre";
cd ./$fic;
exploreEtTraite $fic;
cd ..;
else
echo "ce n'est pas un dossier";
ext=$(echo "$fic" | grep -oE ".html" );
echo "son extension : $ext";
if [[ $ext == ".html" ]]
then
echo "c'est un fichier html, on lance traitement()";
traitement $fic;
else
echo -e "$fic n'est pas un fichier HTML\nPAS DE TRAITEMENT";
fi
fi
done
}
Traitement des pages Webs :
Pour traiter toutes ces données, nous nous sommes largement inspirés de notre programme principal, ce à quelques détails près.
Tout d’abord, la somme des données est très importante comparée aux données de notre programme initial (1.9 GB, 17 924 pages web), nous pensons donc ne pas utiliser toutes les ressources que nous avons vus :
- Pour notre plus grand bonheur, toutes les pages du monde sont en utf-8. Étant donné la masse importante de documents à traiter, on ne peut que se réjouir de ne pas rentrer dans les problèmes d’encodage.
- Nous choisissons de ne pas utiliser minigrep pour une question de temps. Rien que pour faire le lynx seul de tous ces fichiers et l’écrire dans le tableau, cela nous a pris une vingtaine de minutes
Pour lemonde:

Pour le washingtonpost.com :

Nous avons repris les commandes classiques pour le traitement des pages :
lynx -dump -nolist egrep -i "$motif" nbmotif=$(egrep -coi "$motif")
Un lynx pour ne prendre que l’essentiel de la page HTML, un egrep qui récupère le motif, et un egrep -c qui compte le nombre de fois que le motif est présent.
Nous avons mis ces lignes de commande dans une fonction (traitement) qui est appelée par la fonction exploreEtTraite () à chaque fois qu’elle rencontre un fichier HTML.
function traitement (){
let "i=i+1";
fichier=$1;
echo "$ième ficier traité";
lynx -dump -nolist -assume_charset=UTF-8 $fichier > /home/guillaume/Desktop/Cours/Programmation-PROJET/SITES-WEB-ASPIRES/dumps_$site/dump_n°$i.txt;
egrep -i "$motif" /home/guillaume/Desktop/Cours/Programmation-PROJET/SITES-WEB-ASPIRES/dumps_$site/dump_n°$i.txt > /home/guillaume/Desktop/Cours/Programmation-PROJET/SITES-WEB-ASPIRES/contextes_$site-$syntagme/contexte_n°$i.txt;
nbmotif=$(egrep -coi "$motif" /home/guillaume/Desktop/Cours/Programmation-PROJET/SITES-WEB-ASPIRES/dumps_$site/dump_n°$i.txt)
printline $i $fichier;
}
Affichage dans le tableau :
Nous avons choisi d’utiliser une fonction printline () qui est appelée à chaque fois que la fonction traitement () s’occupe d’un dossier (certaines balises ont été remplacées par — ou XX afin de ne pas poser de problème sur WordPress).
function printline (){
compteur=$1;
fichier=$2;
echo "-- --=\"XX\">$compteur --=\"$(pwd)/$fichier\">lien n°$compteur< -- --=\"/home/guillaume/Desktop/Cours/Programmation-PROJET/SITES-WEB-ASPIRES/dumps_$site/dump_n°$compteur.txt\">DUMP_n°$compteur.txt< -- --=\"/home/guillaume/Desktop/Cours/Programmation-PROJET/SITES-WEB-ASPIRES/contextes_$site-$syntagme/contexte_n°$i.txt\">DUMP Contexte n°$compteur< --$nbmotif< --> $tablo;
Pour cette fonction, nous avons du passer par la commande pwd pour indiquer le chemin. Étant donné que nous utilisons une fonction récursive qui va aller fouiller dans les dossier, on ne sait pas trop où l’on se situe. On affiche donc le chemin où l’on la commande se trouve à l’instant t.
Utilisation d’une feuille de style
Afin d’améliorer le rendu du tableau final, on utilise une feuille de style .css.
Pour la créer, nous avons utiliser un éditeur de style en ligne (http://divtable.com/table-styler/).
On dispose de la feuille de style dans le même dossier que le tableau, et on ajoute une référence en début de page HTML qui fait le lien entre ces deux fichiers.
On obtient alors le (très joli) résultat suivant :
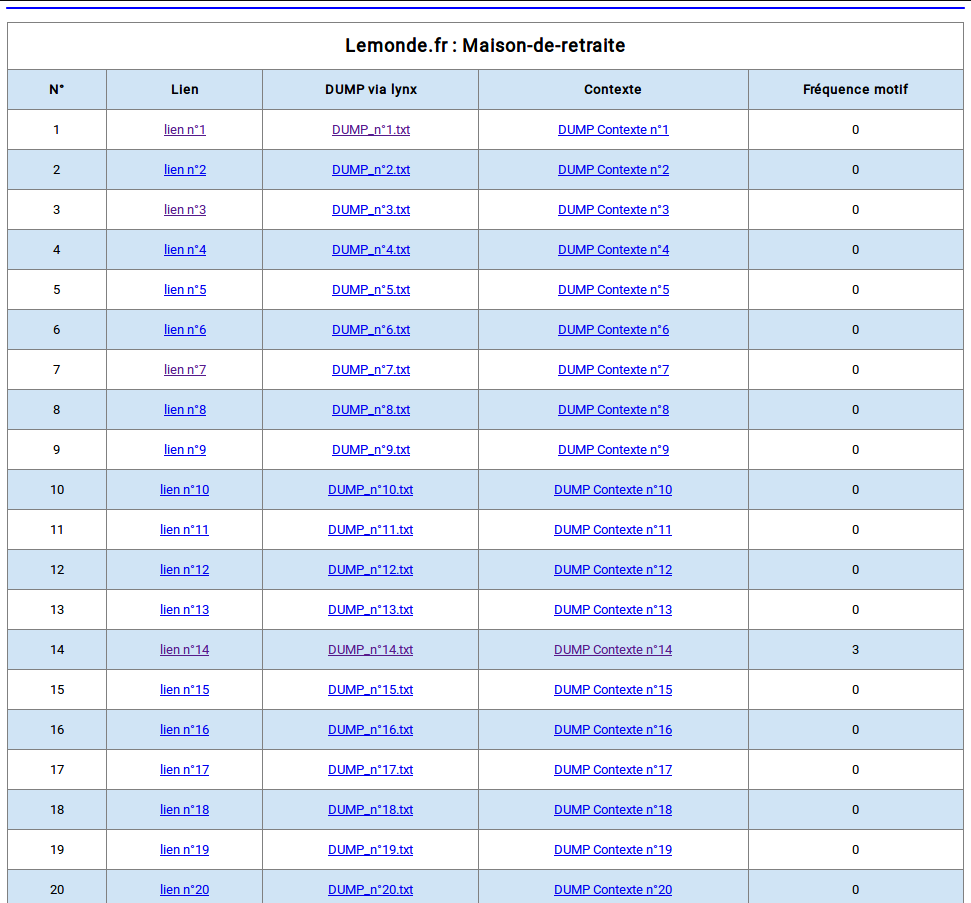
(la taille du fichier HTML est de 12 MB)
Concaténation des fichiers
Comme la masse de donnée est très importante pour nos capacités, nous avons préféré créer un autre script pour concaténer tous les résultats.
#!/bin/bash #concatene_1.0.sh START=$(date +%s.%N); i=0; rep=/home/guillaume/Desktop/Cours/Programmation-PROJET/SITES-WEB-ASPIRES/contextes_washingtonpost.com-Maison-de-retraite; echo "">CONCATENATION-washingtonpost.com-Maison-de-retraite.txt; for fic in $(ls $rep) do let "i=i+1"; echo "$fic"; echo "" >> CONCATENATION-washingtonpost.com-Maison-de-retraite.txt; cat $(echo "$rep/$fic") | sed -r 's/]*>//g' | tr -d '' >> CONCATENATION-washingtonpost.com-Maison-de-retraite.txt; echo "">> CONCATENATION-washingtonpost.com-Maison-de-retraite.txt; done END=$(date +%s.%N); DIFF=$(echo "$END - $START" | bc); echo -e "\n\n\n\n__________________________\nréalisé en $DIFF secondes"; echo "$i fichiers traités";
Résultats
Pour la maison de retraite, les résultats sont assez maigres comparés au poids des données : il s’agit d’un syntagme assez rare. Pour 1.9 GB de pages web, nous n’avons que 12 kb de contextes (environs 200 lignes). Néanmoins, voici les résultats que nous avons obtenus pour le site lemonde.fr et pour maison de retraite (dans un nuage de mots) :

Résultats du Washingtonpost et de maison de retraite :
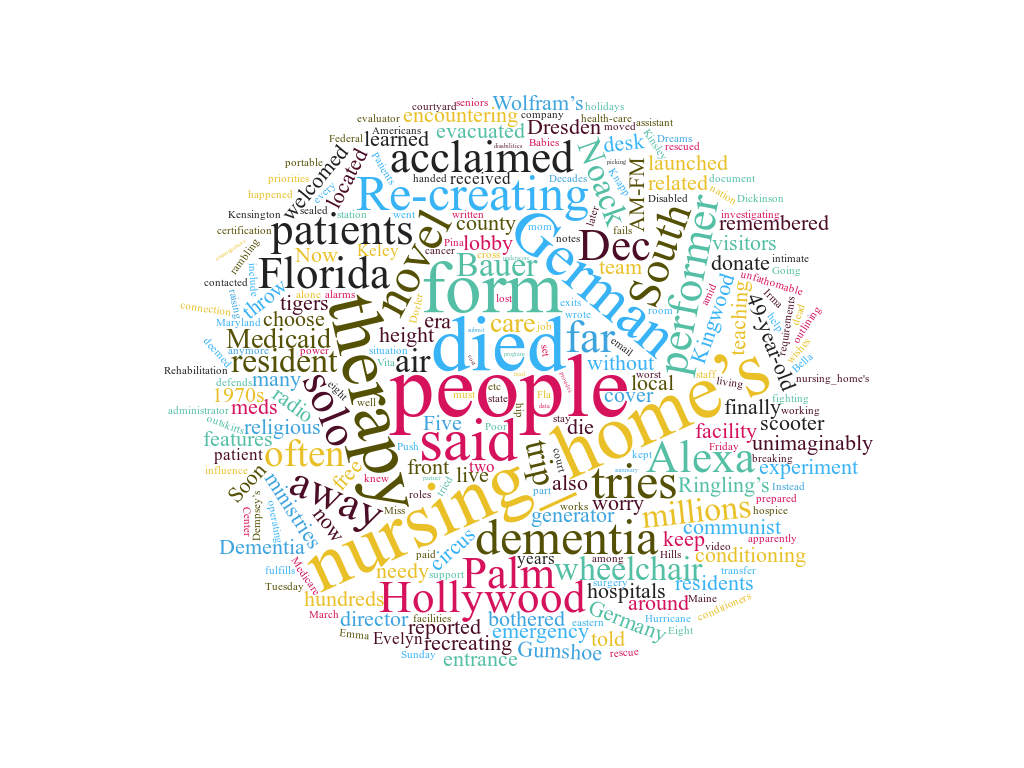
Comparé aux résultats obtenus dans notre travail initial, on peut voir que les résultats de l’anglais ne sont pas exactement les mêmes que pour nos 50 URLS. Tout d’abord, le thème de l’argent est moins présent. On peut essayer d’expliquer cela par le fait que lors du choix de nos URLS, les pages web qui sont ressorties du moteur de recherche étaient celles qui étaient jugées les plus intéressantes (le plus de like). Ensuite, les résultats sont moins portés sur la vie en maison de retraite, mais plutôt sur des termes généraux rattachés au syntagme.
Comme le syntagme n’était pas très présent dans l’ensemble du site, nous pensons ré-exploiter toutes ces données avec un autre syntagme (article à venir).
Le script de ce programme
(les balises ont été retirées pour ne pas perturber l’affichage sur cette page)
#!/bin/bash
#pickup_v2.0.sh
#le syntagme ne doit pas contenir d'espace ni d'underscrore. Uniquement des '-'
#attention, le lynx de traitement () ne doit être fait qu'une seule fois après avoir télécharger le fichier. inutile de le refaire 2 fois
START=$(date +%s.%N);
i=0;
site=washingtonpost.com;
syntagme="Maison-de-retraite";
#le motif est l'expression régulière correspondant au syntagme
motif="[Rr]etirement [Hh]ome(s)?|[Rr]ETIREMENT [Hh]OME(S)?|[Nn]ursing [Hh]ome(s)?|[Nn]URSING [Hh]OME(S)?|[Mm]aisons? [Dd]e [Rr]etraites?|[Mm]AISONS? [Dd]E [Rr]ETRAITES?";
#motif="(donald)? trump";
tablo=/home/guillaume/Desktop/Cours/Programmation-PROJET/SITES-WEB-ASPIRES/tableau_$site-$syntagme.html;
rep=/home/guillaume/Desktop/Cours/Programmation-PROJET/SITES-WEB-ASPIRES/$site;
#########################################################
function exploreEtTraite (){
dos=$1;
echo -e "\n"
echo $(pwd);
echo "dos = $dos";
echo -e "fichiers contenus :\n\n$(ls)";
for fic in $(ls)
do
echo "________________________________";
echo "$fic";
echo $(pwd);
if [ -d ./$fic ] #est-ce un dossier ? :
then
echo "$fic est un dossier, on l'ouvre";
cd ./$fic;
exploreEtTraite $fic;
cd ..;
else
echo "ce n'est pas un dossier";
ext=$(echo "$fic" | grep -oE ".html" );
echo "son extension : $ext";
if [[ $ext == ".html" ]]
then
echo "c'est un fichier html, on lance traitement()";
traitement $fic;
else
echo -e "$fic n'est pas un fichier HTML\nPAS DE TRAITEMENT";
fi
fi
done
}
function traitement (){
let "i=i+1";
fichier=$1;
echo "$ième ficier traité";
lynx -dump -nolist -assume_charset=UTF-8 $fichier > /home/guillaume/Desktop/Cours/Programmation-PROJET/SITES-WEB-ASPIRES/dumps_$site/dump_n°$i.txt;
egrep -i "$motif" /home/guillaume/Desktop/Cours/Programmation-PROJET/SITES-WEB-ASPIRES/dumps_$site/dump_n°$i.txt > /home/guillaume/Desktop/Cours/Programmation-PROJET/SITES-WEB-ASPIRES/contextes_$site-$syntagme/contexte_n°$i.txt;
nbmotif=$(egrep -coi "$motif" /home/guillaume/Desktop/Cours/Programmation-PROJET/SITES-WEB-ASPIRES/dumps_$site/dump_n°$i.txt)
printline $i $fichier;
}
function printline (){
compteur=$1;
fichier=$2;
echo "-- --=\"XX\">$compteur --=\"$(pwd)/$fichier\">lien n°$compteur< -- --=\"/home/guillaume/Desktop/Cours/Programmation-PROJET/SITES-WEB-ASPIRES/dumps_$site/dump_n°$compteur.txt\">DUMP_n°$compteur.txt< -- --=\"/home/guillaume/Desktop/Cours/Programmation-PROJET/SITES-WEB-ASPIRES/contextes_$site-$syntagme/contexte_n°$i.txt\">DUMP Contexte n°$compteur< --$nbmotif< --> $tablo ;
}
#########################################################
#test des répertoires:
#CONTEXTES :
if [ -d $(echo "contextes_$site-$syntagme") ]
then
echo "";
else
mkdir $(echo "contextes_$site-$syntagme");
fi
#DUMPS :
if [ -d $(echo "dumps_$site") ]
then
echo "";
else
mkdir $(echo "dumps_$site");
fi
#########################################################
cd $rep;
#########################################################
#Écriture tableau html
echo -e "--\n--\n --=\"utf-8\">\n--Site WEB aspiré $tablo;
echo " --=\"XX\"> --=\"XX\" XX=\"80%\"/> > $tablo;
echo " -- =\"XX:80%\" XX=\"XX\" XX=\"1\">" >> $tablo;
echo " --=\"7\" XX=\"XX\">------$site : $syntagme< --> $tablo;
echo "-- --=\"XX\">--N°< ----Lien< ----DUMP via lynx< ----Contexte< ----Fréquence motif< --< --> $tablo;
exploreEtTraite $rep;
echo -e "< --\n< --\n> $tablo;
END=$(date +%s.%N);
DIFF=$(echo "$END - $START" | bc);
echo -e "\n\n\n\n__________________________\nréalisé en $DIFF secondes";
echo "$i fichiers traités";
Note : nous avons choisis d’incorporer les fonctions de date du langage bash, afin de connaître le temps d’exécution de notre programme. Nous pensons réutiliser cet outils dans le programme de notre projet.
*un des avantages indirect du bash (langage de bas niveau) est la diminution des frais de coiffeur pour la personne qui code : je pense m’être suffisamment arraché de cheveux sur ces histoires de récursion que je ne pense pas en avoir besoin d’ici 2019.
